DeepSeek V4: Million Context Efficiency
DeepSeek's new million-context model and what this means for Chinese AI.
A few days ago, DeepSeek released their newest model: DeepSeek V4, which coincidentally came right after the release of GPT-5.5 🤔.
While it’s not quite the bombshell that its predecessor was, what they’ve managed to accomplish this time round is still really impressive, managing to cut inference compute and memory costs by creating highly efficient 1 million context models.
But first, some technical details for the nerds 🤓.
Some of the notable architectural changes include:
-
Manifold-Constrained Hyper-Connections (mHC): they improved residual connections between transformer blocks by constraining the residual mapping onto the manifold of doubly stochastic matrices, which enhances signal propagation across deep layers.
-
Hybrid Attention with Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA): CSA compresses the KV cache along the sequence dimension before applying sparse attention, while HCA applies heavier compression to the KV cache but retains dense attention. Working together, they reduce single-token inference FLOPs and KV cache size, which improves efficiency for the model’s 1 million context window.
(More implementation details can be found here.)
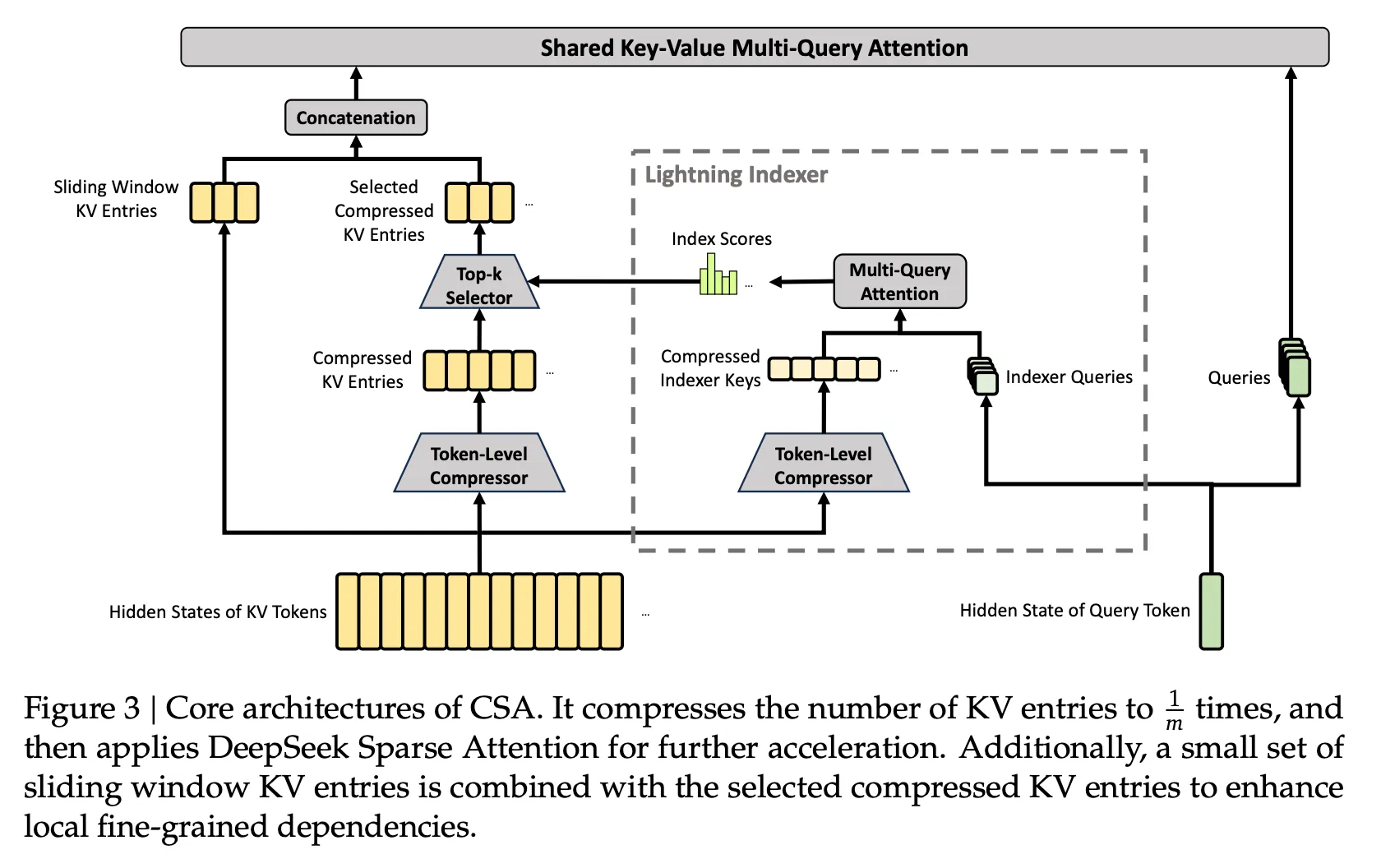
Compressed Sparse Attention (CSA). From the DeepSeek V4 technical report, Figure 3.
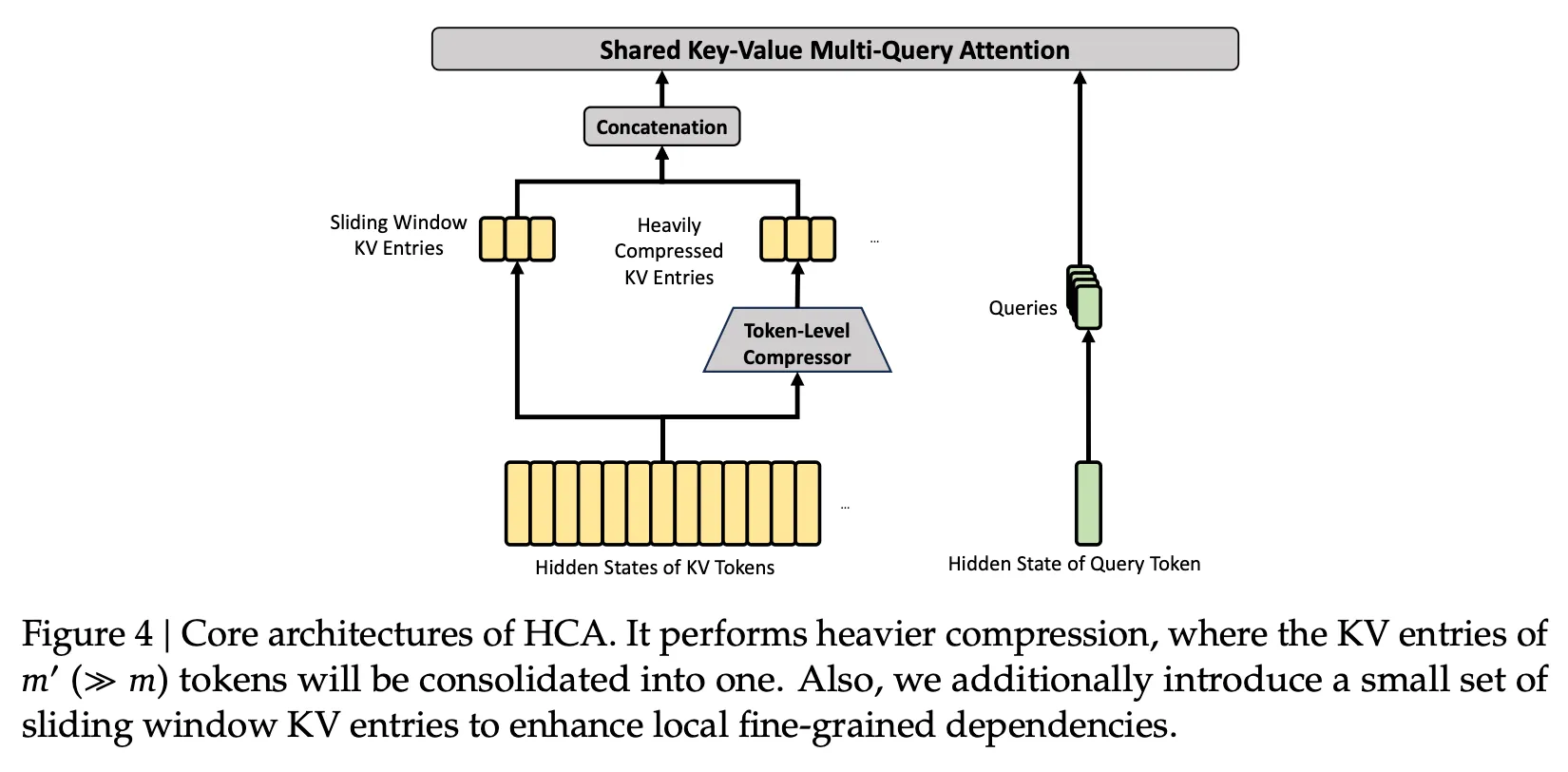
Heavily Compressed Attention (HCA). From the DeepSeek V4 technical report, Figure 4.
-
Muon Optimizer: they used Muon with hybrid Newton-Schulz iterations (similar to Kimi K2) instead of AdamW for most modules to orthogonalize matrices for faster and more stable convergence.
(More about Muon can be found here.)

The Muon optimizer as adapted for DeepSeek V4. Algorithm 1 from the technical report.
-
FP4 Quantization: they applied it to the MoE expert weights and the QK path in the CSA indexer which accelerates attention and cuts memory, featuring a lossless FP4-to-FP8 dequantization pipeline.
-
TileKernels: they used their own Domain Specific Language (DSL) called TileLang to write specialized fused kernels which they claim allowed them to deliver “optimal performance with minimal effort”.
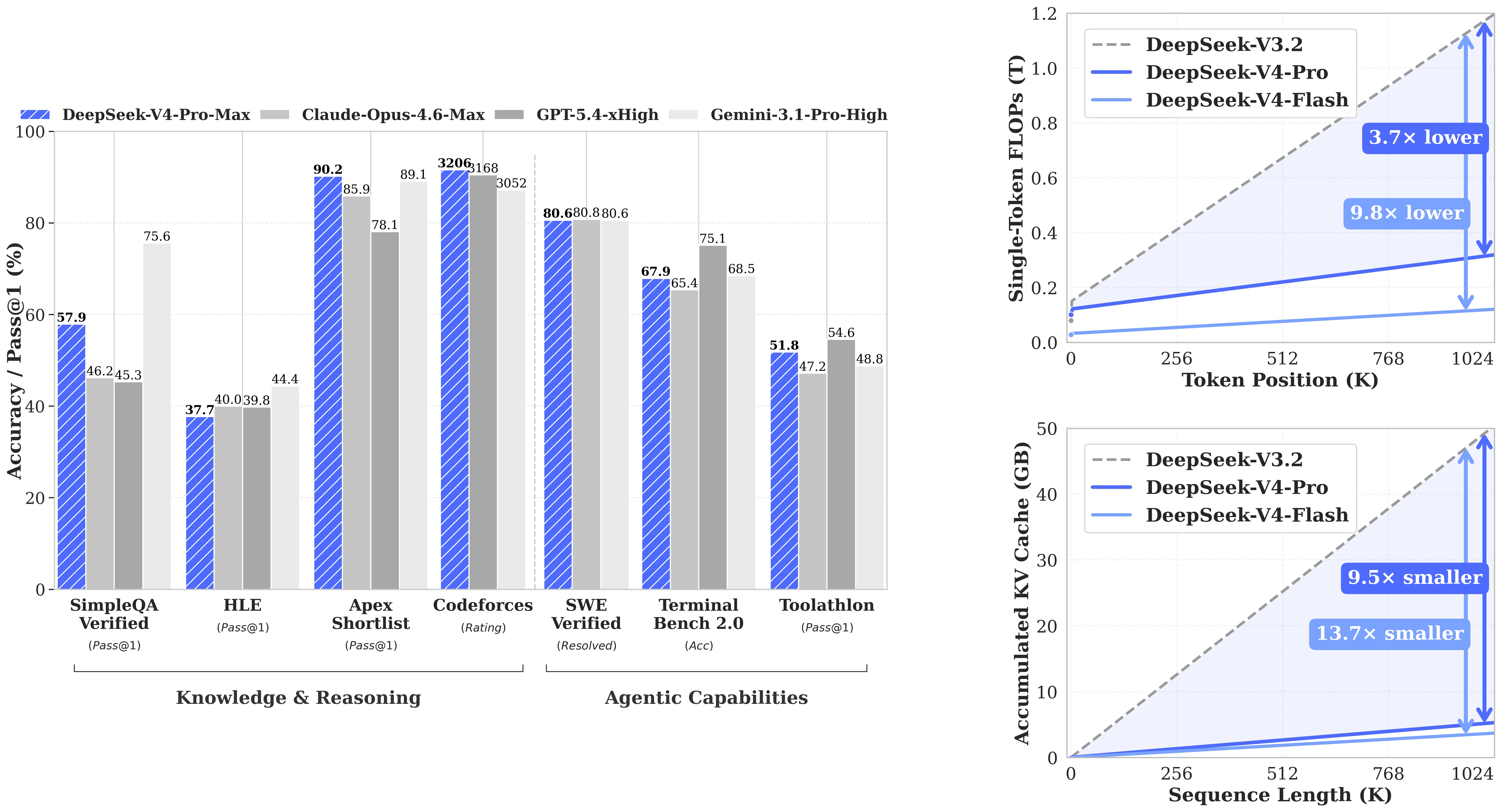
V4-Pro is competitive on most benchmarks while V4-Flash is dramatically cheaper to run at long context.
For those interested, the full technical report can be found here.
While it falls marginally short of frontier models like GPT-5.4, Claude Opus 4.6 and Gemini 3.1-Pro on most standard performance benchmarks, it does achieve top-tier performance in coding benchmarks and might be the most capable million context model for agents.
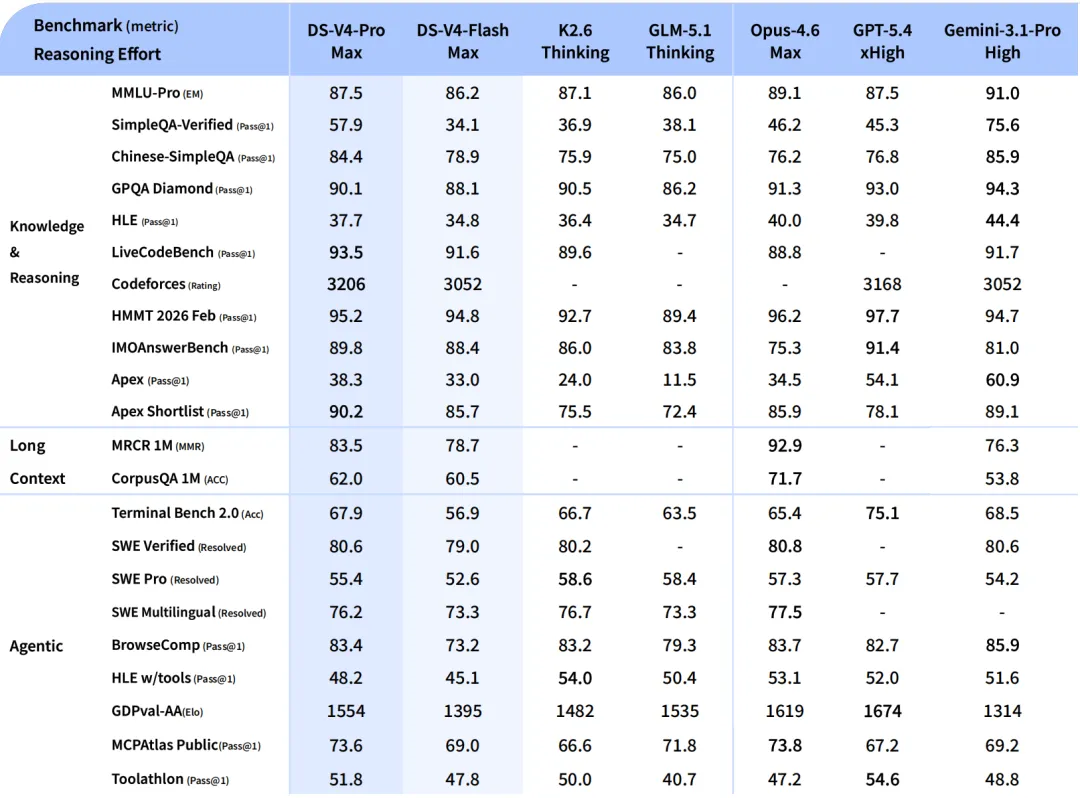
Full benchmarks. V4-Pro is roughly on par with frontier models on most rows and leads on some knowledge and reasoning benchmarks (LiveCodeBench, HMMT, Apex Shortlist).
And although there haven’t been any claims so far that suggest DeepSeek v4 Flash or Pro were trained on HUAWEI Ascend chips with Compute Architecture for Neural Networks (CANN), the model is supposedly optimized for running inference workloads on HUAWEI next-generation Ascend 950PR and 950DT chips, which will be released nearer to the end of the year.
DeepSeek V4’s fine-grained Expert Parallelism (EP) scheme was also validated on “both NVIDIA GPUs and HUAWEI Ascend NPUs”, so this might be them taking a measured step towards potential self-sufficiency by decoupling their AI stack from NVIDIA and running on domestic chips instead.
There’s still a lot more I’d like to unpack with regards to Chinese AI but I’ll leave that for another time 🙃