Gemma 4 & The Future of Local AI
Why Gemma 4 might be the most intelligence-dense open model right now, and the techniques that make it possible.
If you’ve been keeping up with local AI and open-source models, then you’ve probably heard that Google released Gemma 4 about a month back.
I’ve been testing it out a little lately, and I have to say for such a small model, it genuinely does pack a punch (probably the best open model right now in terms of intelligence density — rip Qwen3-4B — which was my previous favourite go-to local model to test and play around with).
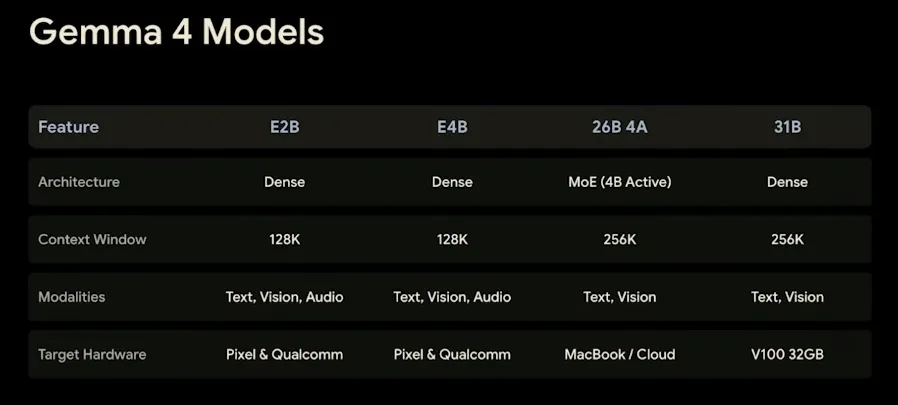
The Gemma 4 model family. From the Gemma 4 Deep Dive by Cassidy Hardin.
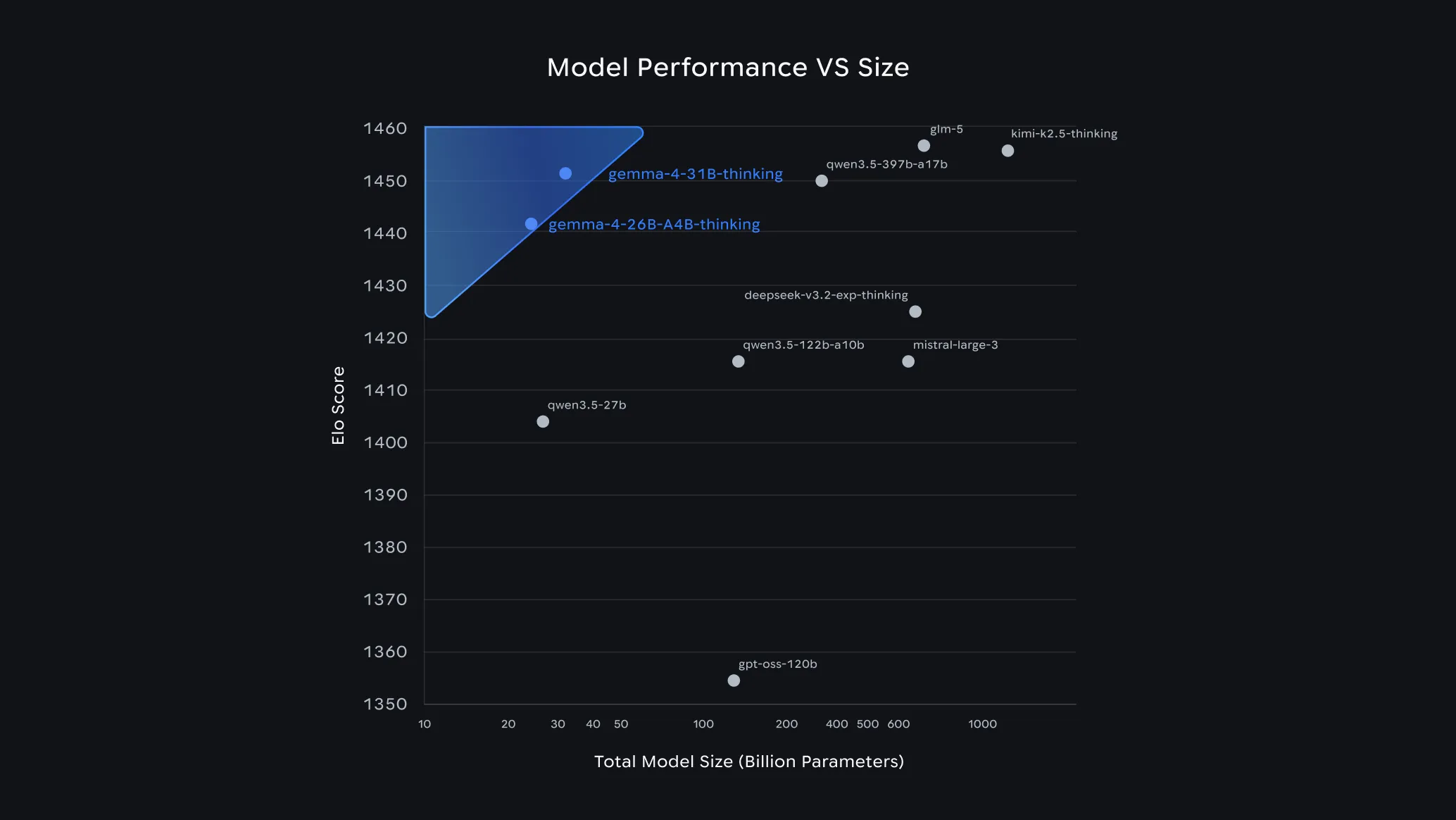
Gemma 4 punches well above its weight class — the highlighted region shows it sitting close to models 10–30x its size.
Some of the key reasons why Gemma 4 was able to pack so much intelligence into such lightweight models include:
- Per-Layer Embeddings (PLE): Previously introduced in Gemma 3n, this adds a parallel, lower-dimensional pathway alongside the main residual stream, giving each layer its own channel to receive token-specific information. Crucially, this PLE table is stored in flash memory instead of VRAM, saving massive amounts of parameter space for the smaller E2B and E4B models.
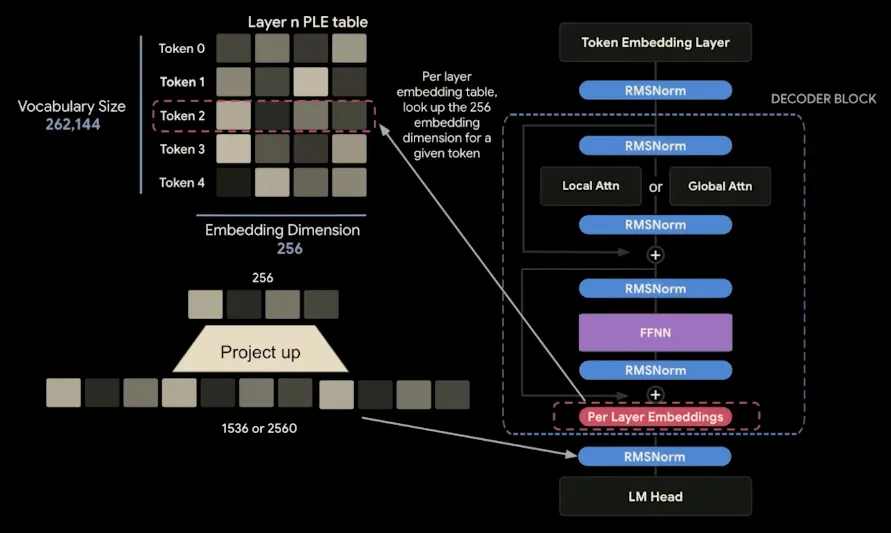
Visualization of how Per-Layer Embeddings (PLE) work.
- Alternating Attention: They alternate between local sliding-window (512 tokens for small models, 1024 for larger models) and global full-context attention layers, utilizing a Dual RoPE configuration (standard RoPE for sliding layers, pruned RoPE for global layers) to enable longer contexts up to 256K. They also use a 5:1 ratio of local-to-global layers (4:1 for the E2B model) where the last layer is always global (attending to all preceding tokens). To offset memory costs, Grouped Query Attention (GQA) is used, grouping 8 queries to 1 key/value head for the global layers and 2 queries for the local layers.
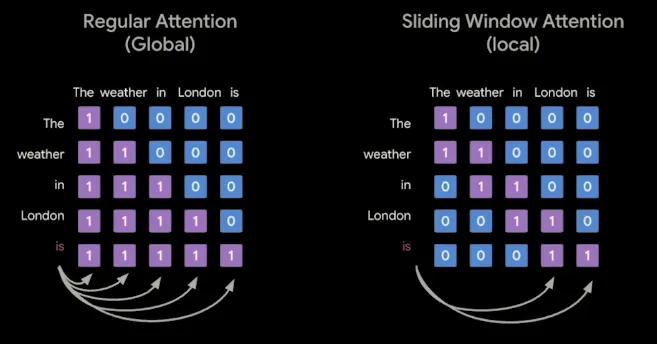
Regular Attention vs. Sliding Window Attention.
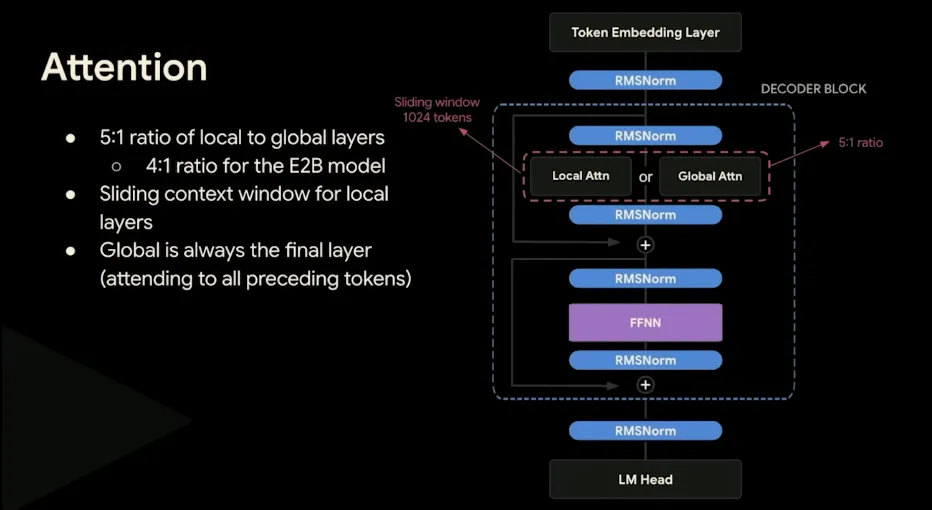
5:1 local-to-global layer ratio (4:1 for E2B model) inside each decoder block, with the final layer always global.
- Mixture of Experts (MoE): The 26B A4B model utilizes an MoE architecture with 26 billion total parameters but activates only ~3.8 billion during inference, delivering incredibly fast tokens-per-second. It uses a router to select from 128 total experts (8 activated per pass), alongside 1 constant shared expert (3x the size of a regular expert) that activates on every single pass.
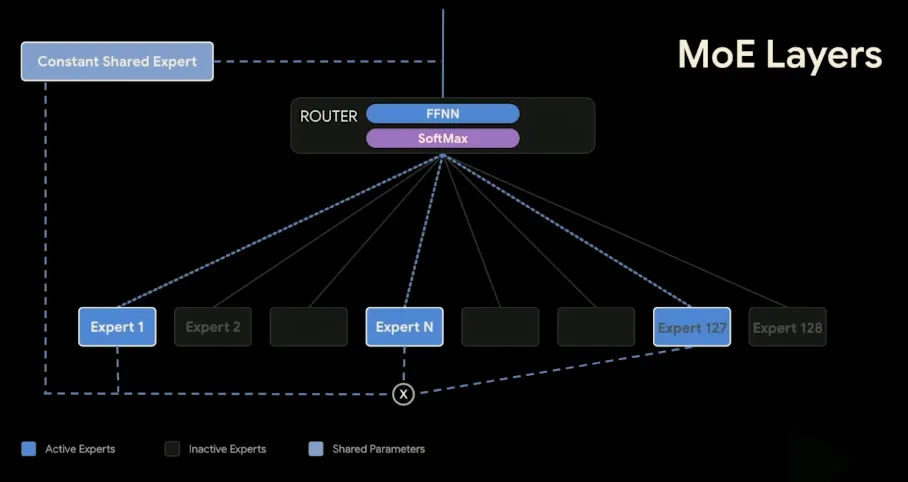
Router picks 8 of 128 experts per pass, with one always-on shared expert.
- Multimodal Encoders: The vision encoder (550M parameters for larger models, 150M for edge models) supports variable aspect ratios and configurable image token budgets (ranging from 70 to 1120 tokens) by cleverly pooling 3x3 grids of image patches into single embeddings. Additionally, the E2B and E4B edge models feature a 305M parameter USM-style conformer for native audio processing.
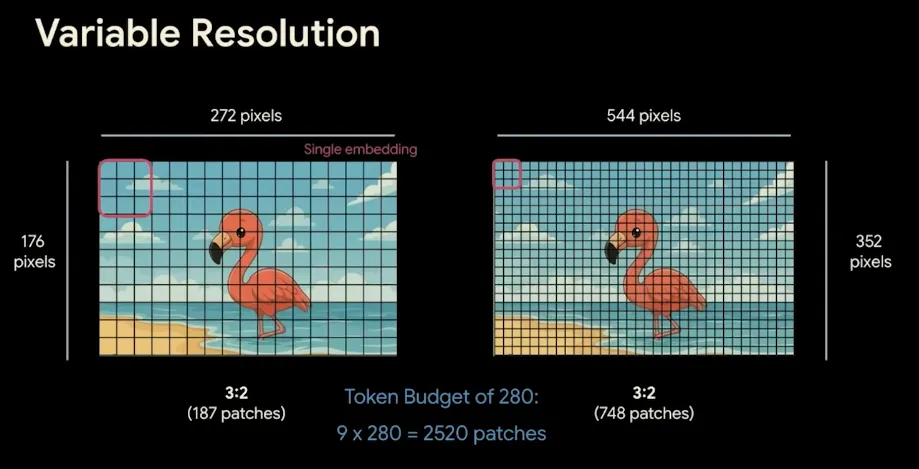
Variable resolution with 3x3 patch pooling.

Edge models get native audio via a 305M-parameter USM-style conformer that processes embeddings rather than tokens.
Perhaps the most important thing beyond all this is that Gemma 4 has officially been moved to an Apache 2.0 License. 🥳
If you haven’t tried it out already, you can check out the E4B and E2B versions (“E” just stands for “effective” parameters here) on Google AI Edge Gallery:
Or if you happen to have a GPU lying around (or access to the compute necessary), the larger 26B MoE and 31B Dense models are available on HuggingFace as well.
There’ve also been many Gemma variants that have been released over the past year or so like TranslateGemma, MedGemma, FunctionGemma, and ShieldGemma to name a few.
And Google has been collaborating with partners like Cactus and Unsloth to foster the ecosystem for the fine-tuning and inference of local models.
Honestly, I have nothing but the utmost respect for the researchers and teams who continue to do the amazing work of innovating and releasing open models for everyone to use, redefining what is possible for what it means to democratize the benefits of AI.
If you’re interested in exploring open models and perhaps even how they can be used for good, check out the Gemma 4 Good hackathon and other really cool projects like SEA-LION which have models that have been continuously pre-trained on top of Gemma 3 previously.
Other relevant links: